Quick Sort
분할할 축값을 정하는 방법의 개선
Random vs Median-of-Three
삽입정렬을 소구간에 적용하는 방법
Partition을 사용해서 selection 문제를 해결할 수 있음
1. Divide and conquer (partition) algorithm
pivot
왼쪽: pivot(축) value 보다 작은 값
오른쪽: 큰 값
partition
template <class TYPE> int partition(TYPE a[], int n) { TYPE v, t; int i, j; v = a[n - 1]; i = -1; j = n - 1; while (true) { while (a[++i] < v); // 왼쪽부터 v(pivot value) 보다 큰 값 찾음 while (a[--j] > v); // 우측부터 v 보다 작은 값 찾음 if (i >= j) // 서로 만나면 종료 break; sort_swap(a[i], a[j]); } sort_swap(a[i], a[n - 1]); // pivot값 v가 가장 큰 최초 위치로 이동 return i; // 가운데 기준으로 좌측은 작은값, } // 우측은 큰값 |
2. Quick sort algorithm
크기가 1 보다 클 동안 partition을 재귀적으로 반복
모두 교환하지 않기에 효율적 (sparingly exchange)
quick sort는 큰 data set에 유리함
개선된 알고리즘 (3가지 방식)을 적용하면 worst case도 O(N*logN) 성능
작은 data set에 대해서는 insert sort가 유리함
code
재귀 code
template <class TYPE> int partition(TYPE a[], int n) { TYPE v, t; int i, j; v = a[n-1]; i = -1; j = n - 1; while (true) { while (a[++i] < v); while (a[--j] > v); if (i >= j) break; sort_swap(a[i], a[j]); } sort_swap(a[i], a[n-1]); return i; } template <class TYPE> void quick_sort(TYPE a, int n) { int i; if (n > 1) { i = partition(a, n); quick_sort(a, i); quick_sort(a+i+1, n-i-1); } } template <class TYPE> void quick_sort_recursive_ver(TYPE a[], int n) { TYPE v, t; int i, j; if (n > 1) { v = a[n-1]; i = -1; j = n-1; while (true) { while (a[++i] < v); while (a[--j] > v);
if (i >= j) break; sort_swap(a[i], a[j]); } sort_swap(a[i], a[n-1]); quick_sort_recursive_ver(a, i); // left side quick_sort_recursive_ver(a+i+1, n-i-1); // right side } } |
반복 code
template <class TYPE> void quick_sort_repetition_ver(TYPE a[], int n) { TYPE v, t; int i, j; int l, r; // range info to store in the stack ListStack<int> stack; l = 0; r = n-1; stack.push(r); stack.push(l); while (!stack.is_empty()) { l = stack.pop(); r = stack.pop(); if (r+l+1 > 1) { // exit condition r+l+1 means range length v = a[r]; i = l-1; j = r; while (true) { while (a[++i] < v); while (a[--j] > v); if (i >= j) break; sort_swap(a[i], a[j]); } sort_swap(a[i], a[r]); stack.push(r); stack.push(i+1); stack.push(i-1); stack.push(l); } } } |
d
test code
void sort_test_entry(void) { int vals[] = {7, 3, 4, 2}; unsigned int i; int rand_vals[SORT_MAX_RAND_LEN]; srand(time(0)); for (i = 0; i < SORT_MAX_RAND_LEN; i++) { rand_vals[i] = rand() % SORT_MAX_RAND_LEN; } sort_select(vals, sizeof(vals)/sizeof(vals[0])); print_array(vals, sizeof(vals)/sizeof(vals[0])); sort_bubble_optimized(rand_vals, sizeof(rand_vals)/sizeof(rand_vals[0])); print_array(rand_vals, sizeof(rand_vals)/sizeof(rand_vals[0])); } |
3. Quick sort 분석
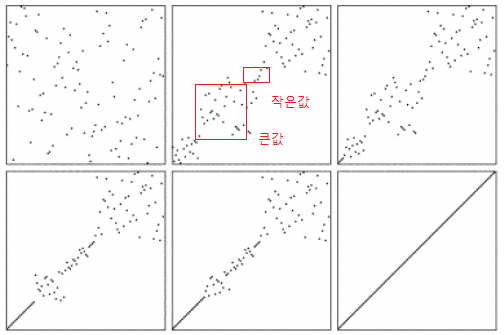
recursive하게 작은 값, 큰 값으로 분류 하다보면 정렬이 완성됨
Best case
분할이 정확히 절반씩 나눠질 때
T(N) = 2 * T(N/2) + N
N개 정렬은 N/2개 (left), N/2개 (right) 처리 시간 소모
left, right에 대해 각각 N/2 번씩 비교
즉, T(N) = O(N logN)
average case
O(N logN)
worst case
분할이 거의 edge에서 이뤄질때, N-1:1
T(N) = O(N^2)
분할이 절반에 가까워야 성능이 좋음
memory usage
stack usage
재귀호출이 stack에 r, l을 저장
worst case
sorted array
2*N
reverse array
2*N+2
best case
2*logN
최악의 경우 stack overflow error 발생 가능
4. Quick sort의 개선
sorted array나 reverse array의 경우 O(N^2)의 성능임
이를 개선하기 위한 방법 (3가지 방법)
난수분할
Media-of-Three 분할
삽입정렬 이용
난수분할
pivot value를 임의로 정함
원래는 pivot 값이 가장 끝 값임 (중간기준으로 비교하며 교환)
끝이 아닌 아무곳의 값을 pivot 값으로 결정
역순/순차에서도
O(N*logN)의 성능
template <class TYPE> void quick_sort_random(TYPE a[], int n) { int i; if (n > 1) { pivot = get_random(n); // 0~n-1 exchange(a[pivot], a[n-1]); // 끝 값을 임의위치 값과 교환 i = partition(a, n); quick_sort(a, i); quick_sort(a+i+1, n-i-1); } } |

Median-of-Three partition
배열의 처음, 끝, 가운데 값 중 가운데 값을 pivot value로 결정
최악의 경우도 O(N*logN)의 성능
왼쪽 아래 쪽의 분홍색은 bubble sort 코드
우측 아래 쪽의 분홍색도 bubble sort 코드


작은 구간은 삽입정렬로 (subfile)
quick sort는 큰 data set에 유리함
작은 data set은 단순 insert sort가 유리함
Media-of-Three + 삽입정렬
이 조합이 가장 좋음


5. qsort 함수
특징
standard library에 존재
#include <stdlib.h>
범용 사용 가능
int intcmp(const void *a, const void *b) { return (*(int*)a - *(int*)b); } int a[1000]; // fill with a qsort (a, 1000, sizeof(int), intcmp); |
6. 성능 비교
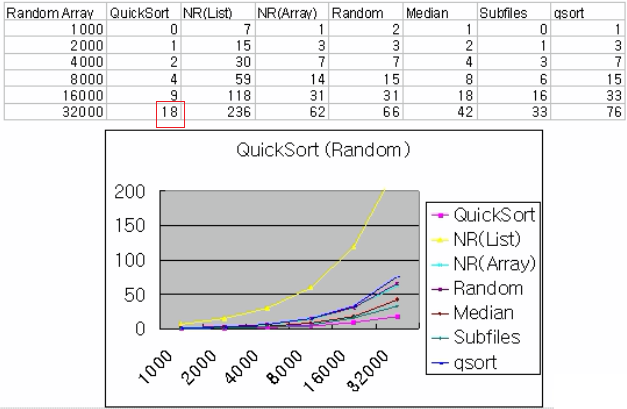
random case (average case)
NR(list ) ← list stack version이 가장 느림 (memory 할당 해제 시간이 제일 많음)
Random, Media, Subfile 모두 QuickSort 보다 연산 량이 많아서 느림
subfile은 Media-of-Three와 Insert sort의 합임
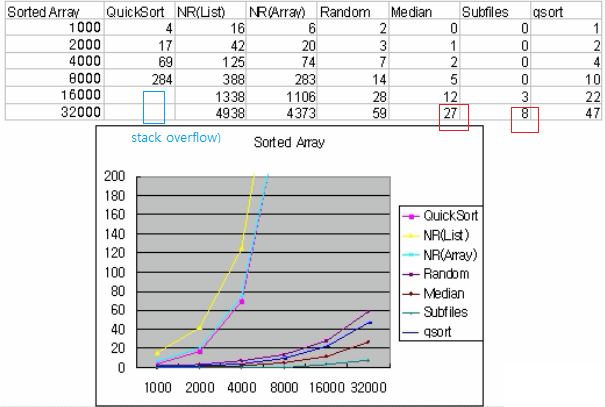
sorted case
sorted array에 대해서는 O(N^2)이 성능이라 NR(List)의 시간이 많아 소모됨
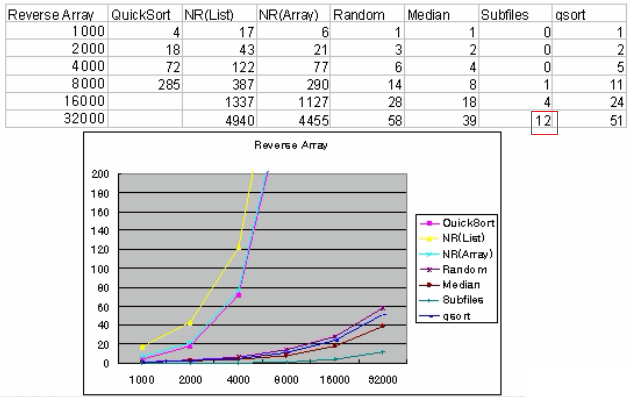
reverse case
6. Selection problem
selection problem ?
정렬 안된 set에서 k-th element 찾기
아무리 좋은 경우라도 O(N*logN)의 시간 소모
단순 해결
selection sort 사용
전체 정렬이 아니라 k-th 원소 찾고 stop
실행 시간은 대략 k*N 번
selection sort 사용
l, r은 left, right 구분
좌하 배열에서 좌측끝이 l, 우측 끝이 r
이 때 k가 3번째라면,
i가 중간이면, k는 좌측에 있으니, 우측은 할 필요가 없음
partition 사용


7. conclusion
Quick sort 알고리즘
분할(partition)을 재귀적으로 수행
pivot value 기준으로 왼쪽은 작은 값, 우측은 큰 값 배치
평균성능은O(N*logN)이나 최악의 경우 O(N^2)
성능 개선 방법
Non-recursive 사용해야 함 (stack overflow 방지)
난수를 이용해 pivot 값을 정하는 방법
Media-of-Three 이용해서 축값 정함
작은 구간에 대해 삽입정렬 사용
subfile = Median-of-Three + 삽입정렬 ← best
partition을 이용한 selection 문제 해결
k 번째 elem 찾는 방법
출처 : http://egloos.zum.com/embedded21/v/1861258
'Algorithm > Theory' 카테고리의 다른 글
| 그래프 탐색 알고리즘(Graph Search Algorithm) (1) | 2022.01.29 |
|---|---|
| 세그먼트 트리(Segment tree) - 구간 합 구하기 (0) | 2018.04.25 |
| 재귀함수의 시간복잡도 (0) | 2018.04.14 |
| 알고리즘 분석 (0) | 2018.04.14 |
| 정렬 알고리즘 - Quick Sort (0) | 2018.04.13 |