머신러닝 시스템 배포

머신러닝 프로젝트 라이프 사이클에서 대분류로 보면, scoping -> data -> modeling -> deployment 순으로 이루어져 있다.
여기서 직관적으로 알기 쉬운 Deployment부터 차례로 알아보도록 하겠다.
1. 머신러닝 시스템 배포 대표적인 패턴
머신러닝 시스템을 배포는 어떠한 방식으로 하는것일까? 머신러닝 시스템을 배포에 가장 흔히 사용되는 케이스에 대해서 알아보도록 하자.
일반적으로 머신러닝 시스템을 배포하는 사용자의 상황은 크게 3개로 나눌 수 있다.
- 새로운 제품이나 새로운 서비스를 시작할때
=> 컴퓨터 리소스를 할당할 때, 작은 트래픽을 지원하는 것부터 시작해서 점차적으로 늘리는 걸 추천한다. 즉, subset부터 테스트를 시작해서 늘리는 방식. - 기존에 사람이 작업하던 Manual task를 머신러닝을 이용해서 작업을 돕거나 자동화하고자 할때
=> Shadow Mode 방식을 추천한다. 예를 들어 만약 공장에서 불량 탐지하는 DL 알고리즘을 돌린다면, 인간과 기계가 같이 수행하는 방식. - 기존 old 한 머신러닝 시스템을 변경하고자 할때.
=> 단순하게 기존 old 시스템과 metric을 비교하면서 프로젝트를 수행하는 방식.
이 각 방식에 대한 것을 스마트폰 화면 스크래치 감시 시스템을 예시로 알아보도록 하자.
1) Shadow Mode Deployment 방식

기존 손수 작업 중이던 작업을 ML 시스템으로 돌린다면 처음 Prototype은 Shadow Mode로 하는 것이 좋다. Shadow Mode는 인간과 기계 동시에 작업하는 것을 의미한다. 그래서 작업자들의 경우에는 ML로 인한 긍정적, 부정적 영향을 전혀 받지 않는다.
말 그대로 처음에는 사람 작업 결과와 ML 시스템의 작업 결과와 정확도를 비교하여 머신의 성능의 신뢰성을 체크함과 동시에 데이터를 쌓아서 좀 더 사람에 가까운 작업을 돕도록 한다.
2) Canary Deployment 방식

어느 정도 머신러닝 알고리즘에 대한 신뢰성 검토가 완료되고 실제 의사결정을 할 수준이 되면, 그다음 일반적인 배포 방식은 카나리아(Canary) 방식이다. 이 방식은 약 5% 정도의 적은 트래픽으로 Roll out 해서 개발한 머신러닝 알고리즘이 적은 컴퓨터 리소스를 투자하여 인간의 일 중 적은 부분만 맡는다.
그리하여, 설령 머신러닝 알고리즘이 어떤 실수를 하더라도, 적은 부분만 영향을 미치게 된다. 따라서 시스템을 더 면밀하게 모니터링할 수 있게 된다. 점점 확신이 들기 시작한다면 점차적으로 트래픽의 비율을 높이면 된다. 이는 조기에 예상치 못한 문제를 발견하고 수정하는 데 도움이 된다.
3) Blue-Green Deployment 방식

일반적으로 기존 알고리즘이 있는 시스템의 경우 Blue-Green 방식을 사용하곤 한다.
대표적인 개념으로, 초록색을 기존 알고리즘. 파란색을 새로 도입할 알고리즘이라고 한다.
이러한 배포 방식에서 라우터가 기존 알고리즘을 토대로 시스템을 돌리다가 새로운 버전으로 갑자기 전환되도록 한다.
이 방식의 가장 큰 장점은 롤백을 사용할 수 있다는 것이다. 문제가 발생하면 라우터를 다시 구성하여 기존 알고리즘이 동작되고 있는 시스템으로 다시 보낼 수 있기 때문이다. 이뿐만 아니라 트래픽을 세분화하여서 10%만 새로운 알고리즘에 트래픽을 쓰다가 천천히 늘릴 수도 있다.
4) 자동화 단계
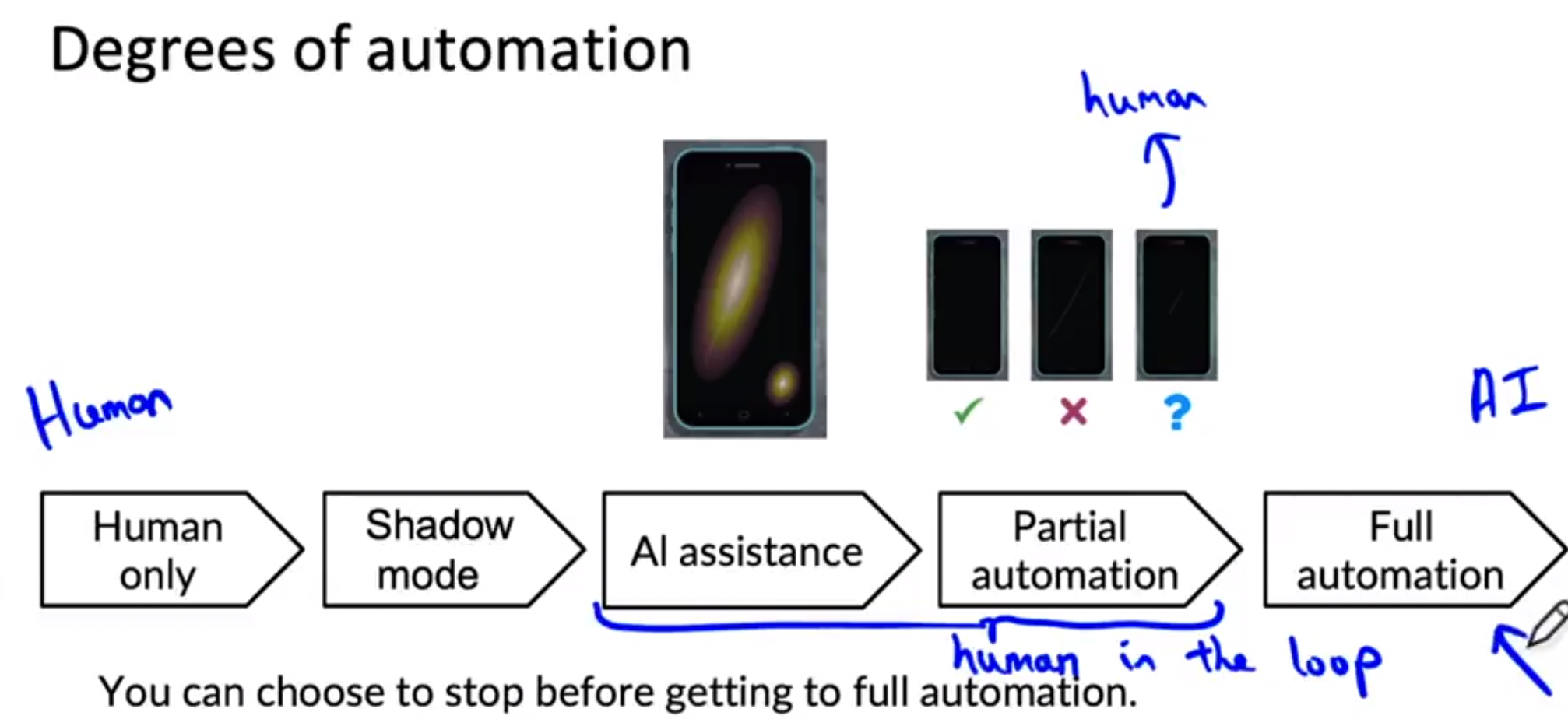
글로써 표현하였지만, 당연하게도 Shadow mode, canary, Blue-Green Deployment 또는 다른 배포 방식을 사용하더라도, 이것을 실행하기 위해서는 꽤 많은 소프트웨어가 필요한다는 것을 알 수 있다. 이때 현업에서는 MLOps 솔루션을 사용하거나 사용자가 직접 구현하여 사용하곤한다.
시스템 배포 방법을 결정할 때, 배포를 한다, 안 한다로 생각하지 않고, 배포를 할 때 현업 시스템에 맞게 적절한 자동화 정도를 고려하여 시스템을 설계하는 것이 올바른 결정 방법이다.
자동화는 인간의 일을 보조하는 AI 보조도구가 될 수 있다. 스마트폰 화면 불량 AI 시스템에서 검사관의 인터페이스에 스크래치가 있는 부분을 강조 시킴으로써 업무 효율 더 높일 수도 있고, 피드백을 통한 학습을 통해 더 높은 수준의 자동화 모델을 만들 수 있다.
그다음으로 부분 자동화는 학습된 알고리즘이 배포해도 괜찮은 수준까지 갔을 때 시행하는 방법이다. 그러나 학습 알고리즘이 확실하지 않는 경우에는, 사람에게 보내서 피드백을 받음으로써 데이터의 퀄리티를 높일 수도 있다. 그러나 사람이 판단하기조차 확실하지 않은 이미지의 작은 부분에 대해서 확실히 관리하도록 한다.
부분 자동화를 넘어 학습 알고리즘이 모든 결정을 내릴 수 있는 완전 자동화가 있다. 많은 배포 애플리케이션은 위 사진에서 왼쪽에서 시작하여 점차 오른쪽으로 이동합니다. 또한 전체 자동화까지 수행할 필요가 없습니다. 시스템의 성능과 애플리케이션의 요구에 따라 AI 지원 또는 부분 자동화 사용을 중지하거나 전체 자동화로 전환하도록 선택할 수 있습니다.
배포를 어렵게 하는게 대표적으로 어떤게 있을까?
대표적으로 2가지가 있다. 첫째는 머신러닝의 통계학적 이슈 둘째는 소프트웨어 이슈라고 할 수 있다. 이에 대해서 좀더 자세히 알아보도록 하자.
2. 머신러닝 시스템 배포를 어렵게 하는 요소들
1) 머신러닝의 통계학적 이슈(Machine Learning Statistics Issue)

머신러닝의 통계학적 이슈라 함은 인풋데이터의 값의 변화로 인해 머신러닝의 시스템의 성능에 이슈가 생기는것을 의미한다. 그 중 대표적인 이슈인 Concept drift과 Data drift에 대해서 알아보자. (이것의 정의에 대해서 많은 사람들의 주장이 있지만, 나는 Andrew Ng 이야기를 기준으로 한다.)
$X$- 모델의 인풋값
$Y$- 학습시킬때 X와 맵핑되는 Y값(True label, Ground True)
$\hat{y}$ - 모델을 거쳐서 나온 예측 결과값.
(1) Concept drift.
Concept drift는 $X->Y$에서 ground true값인 $Y$의 트랜드, 분포가 변하는것을 의미한다.
- 사용자 구매패턴을 기반으로 AI 사기탐지 시스템을 운영한다고 해보자. 이 시스템은 코로나 시대에 접어들면서 오탐이 엄청나게 많이 발생하는 현상이 발생했다. 이는 시스템이 개개인의 구매패턴이 오프라인보다 온라인이 급증하게 되는 것으로 이를 사기로 생각한것이다. 이 문제를 해결하기 위해 머신러닝팀은 오탐을 줄이기 위해서 새로운 데이터를 수집하여 AI하여 모델을 다시 train시켰다 (sudden shock)
- 방의 갯수에 따른 집값을 예측하는 시스템을 있다고 하자. 어느날 인플레이션이 발생한다면, X는 같은데 Y는 변할 것이다. 집 크기는 변하지 않았을지 몰라도 주어진 집값은 달라진다
이처럼 concept drift는 시스템의 통계가 시간이 지남에 따라 바뀌는 문제를 의미한다.
(2) Data drift
Data drift는 $X->Y$에서 입력값 $X$의 트랜드, 분포가 변하는것을 의미한다.
- 집 크기를 입력받아 집값을 예측하는 시스템이 있다고 가정할때, 시대가 지남에 따라 사람들이 더 큰 집을 선호하기 시작하여 큰집을 짓게 된다면 가격은 같은데, 입력값인 X의 입력 분포가 변하게 되는 현상이 발생한다.
가장 중요한거는 많은 변화들을 감지해야한다 $X$가 뭐고 $Y$가 무엇인지 빠르게 파악해야한다는것이다.
추가적으로 이러한 데이터의 변화들을 관리해야한다는거다
2) 소프트웨어 엔지니어링 이슈(Software Engineering Issue)
소프트웨어 엔지니어링 이슈로 인해서 머신러닝 시스템에 악영향이 갈 수 있다.
이러한 고민은 시스템을 어떻게 잘 관리하지에 가까우며 기존 DevOps의 고민들과 유사하다고 할 수 있다.
Andrew Ng은 다행스럽게도 이러한것을 고려하기 위한 소프트웨어 운영 체크리스트를 정의해서 제공해주었는데, 한번 확인해보자.
(1) Realtime Prediction vs Batch Prediction
- Realtime: 자율주행시스템이라고 가정해보자, 계속 연속적으로 들어오는 이미지, 센서데이터(Stream)로 하여금 자동차 제어를 해야한다. 이럴 경우에는 당연히도, Realtime이 필요할것이다. 또다른 예로는, 사용자가 말하고 0.5초 안에 응답을 받아야하는 음성인식 시스템 또한 실시간 예측이 필요할것이다.
- Batch : 직원에게 의사결정을 돕고자 만들어진 한달뒤 라면 가격 예측 시스템이 있다고 생각해보자. 이 시스템은 굳이 바로바로 응답을 할 필요가 없기때문에 연산이 많이 필요한 모델 훈련이나 알고리즘 수행을 직원들이 퇴근하는 밤에 동작시킬수 있다.
(2) Cloud vs Edge/Browser
- 대부분 AI시스템은 고성능을 요하는 작업들이 많기 때문에 클라우드에서 작동시켜서 사용자에게 반환시켜준다. 그러나, 만약에 자동차나 어떤 네트워크가 연결되기 힘든 환경의 시스템은 Edge에서 작동하게 만들어야할것이다.
(3) Compute Resources
- AI 시스템을 돌리기 위해서 무작정 고성능만 바라는것은 좋지 못한방법이다. 일반적으로 딥러닝 엔지니어가 사용하는 Neural Net을 고성능 GPU로 훈련시켰더라도, 서비스를 적용하는 곳에도 똑같이 고성능 배치용 GPU를 설치하기에는 재정적 손해가 발생할 수 밖에 없다. 이때 일반적으로 Deep learning 모델의 복잡성을 줄이거나 압축하기 위한 작업들을 요할 수 잇다. 만약 CPU, GPU 리소스와 예측 서비스를 위한 메모리 리소스 양을 알고 있다면 올바른 소프트웨어 아키텍처를 선택하는 데 도움이 될 수 있으며, 재정적 손해를 줄이는 효율적인 시스템을 구축할 수 있을것이다.
(4) Latency, Throughput(QPS)
- Latency : 시스템에서 0.5초 혹은 500ms 이내에 사용자에게 답변을 받고자 하는 경우가 흔하다. 근데 만약 시스템이 500밀리초 중에서 300밀리초만 음성 인식에 할당할 수 있다고 생각해보자. 이때, Latency를 통해서 이 간극을 매꿀수 있다. 따라서 시스템에 지연 시간이 필요합니다.
- Throughput(QPS) : 현재 가진 연산 리소스에서 처리해야 하는 초당 쿼리 수를 나타낸다. 예를 들어 초당 1000개의 쿼리를 처리해야 하는 시스템을 구축하는 경우 QPS 요구 사항에 부합하기 위해 충분한 컴퓨터 리소스를 확보하도록 시스템을 체크아웃하는 것이 필요하다.
(5) Logging
- 분석 환경을 구축할 때 데이터 분석 및 모델 검토를 위해서는 가능한 많은 데이터를 로깅하고 향후 새로운 학습 알고리즘을 위한 로그 데이터를 제공하는 것이 도움이 되기때문이다.
(6) Security
많이들 간과하는것 중 하나이다. 데이터를 분석하고 이에 대한 결과값만이 중요한것이 아니라, 적절한 보안 데이터레벨을 정해서 처리해야하한다. 예를 들어, 병원 전자 건강 시스템이라고 가정한다면, 환자의 기록들은 사생활을 담고 있는 매우 민감한 정보이기 때문에 보안에 대한 필수요소들을 만드시 지켜야한다. 그러므로 애플리케이션에 따라, 데이터의 민감도에 따라 적절한 수준의 보안 및 개인 정보 보호로 설계해야 할 수도 있습니다.
3. 머신러닝 서비스 모니터링(Monitoring)
머신러닝 프로젝트를 운용하는데 모니터링은 필수조건이다. 모니터링은 머신러닝 모델의 성능을 높일 수 있을뿐만 아니라, 이슈가 생기더라도 로그 데이터를 통해서 대처할 수 있다. 한번 자세히 알아보도록하자.
1) 시스템 모니터링(System Monitoring)

머신러닝 시스템을 모니터링하는데에 가장 일반적인 방식은 위 그림처럼 대시보드(Dashboard)를 사용해서 시간에 따른 시스템의 상태를 트래킹 하는것이다.
2) 데이터 모니터링(Data Monitoring)
그렇다면, 시스템의 상태가 아닌 데이터의 상태는 어떻게 모니터링 할까? 음성인식 시스템(Speech Recognition)을 예로 들어보자.

음성인식 시스템에서 사용자가 말하기 전/후 공백은 일반적으로 Null로 처리한다. 그런데, 만약 어느날 급격하게 Null의 비율이 변화한다면 무언가가 잘못되었다는 표시일 수도 있다.

그래서 일반적으로는 어떠한 임계치(thresholds)를 설정해두고 이 범위를 넘어가면 관리자에게 알람을 울리는 식으로 시스템을 기획하곤 한다.
3) 에러 지표 브레인 스토밍(Braningstorming Error Index)
무엇을 모니터링해야할지 결정할 때는, 데이터든 시스템이든 잘못될 수 있는 모든 것들을 브레인스토밍하는 것이 중요하다. 머신러닝 시스템이 잘못될 수 있는 모든 문제에 대해서 모니터링할 방법에 대해서 통계나 metric를 현업 담당자, 개발자, 모두 포함하여 브레인스토밍하는것이 중요하다.
예를 들어, 사용자 트래픽이 급증하여 서비스가 오버로드(overload)될까 걱정되는 경우 위 그림에서 나와있듯, server load metric 하나면 모니터링 할 수 있다. 모니터링 대시보드를 처음 설계할 떈 다양한 메트릭으로 시작하여 비교적 큰 세트를 모니터링하고 시간이 지나면서 유용하지 않다고 판단되는 메트릭을 점차 제거하는 것이 좋다.
본 포스팅은 Coursera의 MLOps 특화 과정을 학습하며 정리한 정리노트입니다.
'AI > MLOps' 카테고리의 다른 글
| (2) 머신러닝 프로젝트: 기획부터 배포까지 (0) | 2022.01.11 |
|---|---|
| (1) What is the MLOps? (0) | 2022.01.07 |
| 0. MLOps 공부 자료 (0) | 2022.01.03 |