1. CNN의 탄생 배경

과거에는 DNN(Deep Neural Net)을 이용해서 손글씨, 옷 이미지 데이터를 예측하는 일을 했다.
여기서 2가지 문제가 발생하게 된다.
1) 학습 효율성, 속도
문제이미지가 28x28로 엄청 작아도 DNN를 사용하고자 한다면, 입력노드를 2352개 써야한다. 이는 지나치게 많은 입력 노드가 발생하여 효율성이 떨어진다.
2) Overfitting 문제
가령 흰배경에 강아지가 있는 사진만을 학습시킨 모델에 테스트 이미지로 검은 배경의 강아지가 들어왔다고 해보자. DNN학습된 이미지는 이게 강아지임을 분류 하기란 쉽지않다. 그리고 오버피팅을 야기할 수 있다.
이를 해결하고자 1998년 Yann LeCun이 더 잘 작동시키는 아이디어로 논문을 썼는데 그것이 컨볼루션 네트워크(Convolutional Neural Network, CNN)이다.
2. CNN 아이디어
기본적으로 DNN이 이미지를 통해 추측하는 방식은 그림의 모든 픽셀을 하나씩보고 "아, 저 픽셀 값이 87이고 저 픽셀은 127 값을 가지고 있으니 80% 확률로 신발이야!"와 같은 식으로 추측했었다.
반면, CNN은 사진을 보고 Convolution을 진행하면서 이미지의 특징(feature)과 특징들을 뽑아낼 수 있는 필터(filter)를 학습시킨다. 이후 DNN을 진행하게 되는데, 과거에는 픽셀단위로 보던것이, feature단위로 보게 되면서 컴퓨터는 이제, "오, 끈.. 밑창..이 보이네 그럼 이건 신발 혹은 핸드백이 겠네? 어? 근데 끈 보다는 손잡이였고, 직사각형 가방 느낌이네? 이건 핸드백이다!"와 같이 추론할 수 있게 되는것이다.
이제 그러면 이 아이디어를 이용해서 코드에서는 어떻게 사용하는지 한번 살펴보도록 하자.
+) Stride, Zero padding와 같은 개념들은 DNN, CNN, RNN까지 모두 진행한후 설명하도록 하겠다.
1) 필터(Filter)
CNN의 학습방식은 필터(filter)를 통해서 이미지의 특징(feature)를 잡아낸다.


필터는 우리가 흔히 생각하듯 걸러내는 작업이다. 위 필터의 예시를 보자. vertical 필터 예시 경우 왼쪽 이미지에서 모든 픽셀들에 대해 filter를 거치면 세로 선만 추출하며, 그 밑 예시 또한 가로선만 추출하는 것을 볼 수 있다.

계산은 위와 같이 할 수 있다. Fashion-MNIST 데이터 셋중 신발의 예시로 필터가 적용되는 살펴보자. 파란색으로 동그라미 쳐진부분에서 3x3 픽셀만 살펴보면 해당 부분과 필터와 1:1 매칭으로 곱하기를 걸쳐서 새로운 이미지 값을 뽑아낸다.
2) 풀링(Poolling)

풀링은 위와같다. 어떠한 4x4 픽셀의 이미지가 있다고 할때, 해당 이미지에서 강조되는 부분은 보존하고 이미지를 압축시키는 기법이다.
위의 예시는 4x4를 2x2로 이미지를 압축시키는 풀링과정에 대한 예시로 볼 수 있다.
3. CNN 구현
1) 코드 설명
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(64, (3,3), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])맨아래 3줄만 본다면 DNN으로 신발이미지를 학습시키는 코드와 동일하다. Convolution이 적용되는 과정을 보자. 입력값은 28x28 동일하므로 input_shape은 동일하다.
- Line 02: 첫번째 Convolution은 Keras가 64개의 필터를 생성하라고 요청하고 그 필터는 3x3으로 요청한다. 그리고 활성함수(activation function)은 relu를 사용하며 이것은 음수가 나오면 0으로 처리하는거다. 참고로 위에 정의한 64 필터의 값은 무작위값이 아니다. 각 필터들은 keras에 기존에 설정된 매우 잘 알려진 필터 세트를 시작으로 이 세트에서 작동하는 필터들은 점차적으로 학습이 되는것이다.
- Line 03: 2x2 max pooling을 통해서 4 픽셀 중 가장 큰 픽셀값을 가진 것을 적용시킨다.
- Line 04-5: 위와 같은 형식으로 기존 컨볼루션 위에 다른 컨볼루션 세트를 학습하고 다시 max pooling 레이어를 추가한다.
- Line 06: 이제 Flatten으로 펴지게 되는데 이거는 MaxPoolling을 통해서 1/4 그리고 1/4가 된다.
- Line 07-8: 필터로 잡아낸 필터만을 토대로 학습을 진행한다.
이 Convolution의 목적은 필터들이 이미지의 특징들만 추출하고 이후 DNN으로 이를 학습시키는거다.
이를 통해서 기존 DNN에서 겪고 있었던 학습 효율성 문제나, 오버피팅 문제를 방지 할 수 있는것이다.
2) model.summary
학습시킨 모델을 model.summary 명령어를 실행하면 학습하면서 각 레이어에서 일어나는 일들을 볼 수 있다.

위 코드도 차례차례 확인해보자.
(1) 28x28이 아닌 26x26?

보면 우리가 작성한 인풋으로 작성한 코드인 28x28이 아니라 26x26으로 결과값이 나온다. 무슨일일까?
우리는 작성한 코드를 살펴봤을때 필터가 3x3였던걸 확인할 수 있다.

28x28 이미지에 필터를 적용시킬때 일어나는 일을 확대해서 보면, 필터를 적용하려면 왼쪽, 중간 이미지에 해당하는 부분을 기준으로는 3x3 필터를 적용시킬수 없다. 반드시 가장 오른쪽 이미지처럼 3x3 계산이 가능한 형태여야 한다는것이다.
이처럼 가로세로 양쪽에 마진(margin)이 제외하여 필터가 적용되고나면 28x28이 아닌 26x26이 결과값으로 반환된다.
(2) Max pooling의 Output 13x13

인풋으로 26x26을 2x2 max pooling을 진행하게되면 당연히 가로 세로로 1/2만큼 줄것이다
이에 따라 26 => 13으로 바뀐다는것은 쉽게 알 수 있다.
(3) 또 다른 Conv

3x3으로 진행되는데, 1)과 동일하게 마진(margin) 2픽셀이 사라지는것을 볼 수 있다.
(4) 다시 Max pooling

11x11의 이미지를 2x2 Max pooling을 진행하므로 1/2 하고 나머지를 버린 5x5 형태로 결과값이 반환 될것이다.
(5) Max pooling의 Output 13x13

이로써 28x28이미지 픽셀값인 784개의 입력노드에서 5x5x64 로 1600개의 입력노드로 증가시켰다.
+) 입력노드가 증가
(6) DNN 진행

3) CNN 결과 확인
CNN 각 단계에서 나타나는 결과를 확인해보도록 하자.
import matplotlib.pyplot as plt
from tensorflow.keras import models
layer_outputs = [layer.output for layer in model.layers]
activation_model = tf.keras.models.Model(inputs = model.input, outputs = layer_outputs)
f_test, axarr_test = plt.subplots(1,5,constrained_layout=True)
axarr_test[0].imshow(test_images[0], cmap='inferno')
for x in range(0,4):
f1_test = activation_model.predict(test_images[0].reshape(1, 28, 28, 1))[x]
axarr_test[x+1].imshow(f1_test[0, : , :, 1], cmap='inferno')- Line 01-2: 관련된 라이브러리를 import 한다. 시각화를 위한 matplotlib 그리고 각 layer별로 결과를 확인하기 위해 models 라이브러리를 불러온다.
- Line 04: 위 model 각 Layers의 아웃풋들을 lamda 함수를 통해서 리스트에 저장한다.
- Line 05: model 인풋과 아웃풋들을 설정한다.
- Line 07: 총 5개의 plot을 한 행에 나타내는데 최적의 간격으로 표현한다.
- Line 08: 첫번째 plot은 test할 이미지를 표현하고
- Line 10-11: 각 모델에 테스트할 데이터를 넣고 이때 나타나는 결과값을 출력한다.
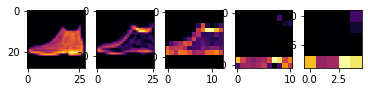
위 코드의 결과값은 위와같다.
가장 왼쪽은 테스트할 데이터의 이미지, 이후 각 결과값 (1, 26, 26, 32) (1, 13, 13, 32) (1, 11, 11, 32) (1, 5, 5, 32)의 shape으로 특징들을 잡는 모습을 확인할 수 있다.
4) DNN vs CNN 성능 비교
(0) 시스템 성능
CPU
RAM: 26GB
GPU: Tesla T4
(1) DNN
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
# Setup training parameters
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# Train the model
print(f'\nMODEL TRAINING:')
model.fit(training_images, training_labels, epochs=5)
# Evaluate on the test set
print(f'\nMODEL EVALUATION:')
test_loss = model.evaluate(test_images, test_labels)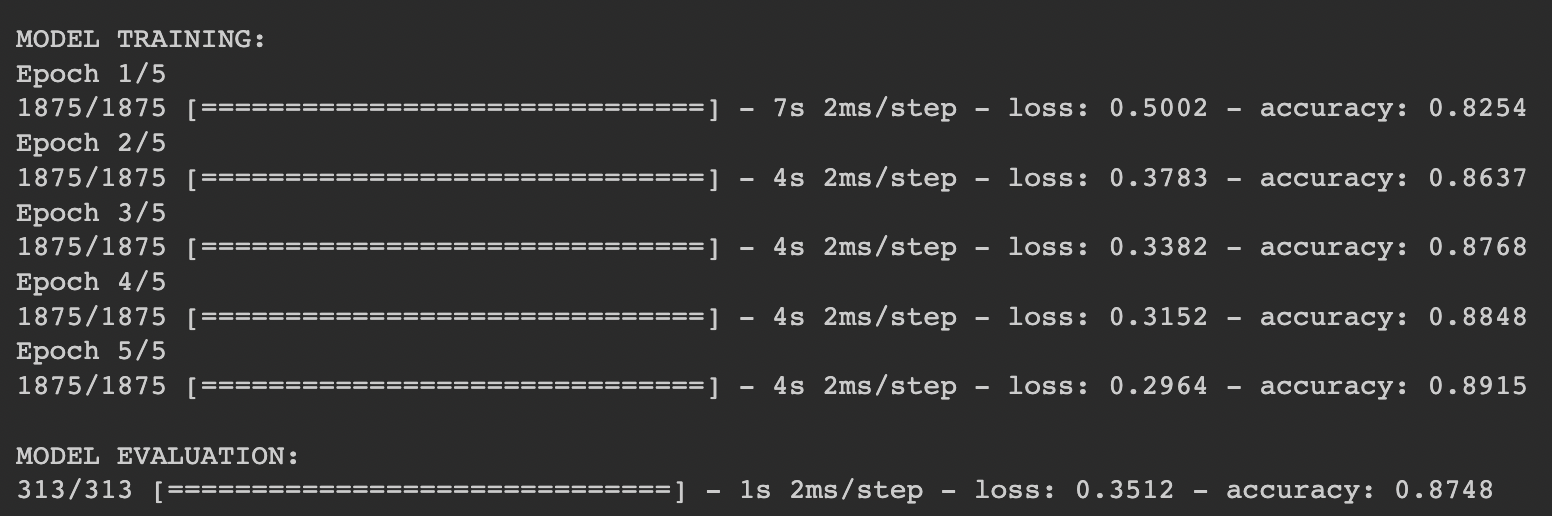
(2) CNN
model = tf.keras.models.Sequential(\[
# Add convolutions and max pooling
tf.keras.layers.Conv2D(32, (3,3), activation='relu', input\_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
# Add the same layers as before
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
\])
# Use same settings
model.compile(optimizer='adam', loss='sparse\_categorical\_crossentropy', metrics=\['accuracy'\])
# Train the model
print(f'\\nMODEL TRAINING:')
model.fit(training\_images, training\_labels, epochs=5)
# Evaluate on the test set
print(f'\\nMODEL EVALUATION:')
test\_loss = model.evaluate(test\_images, test\_labels)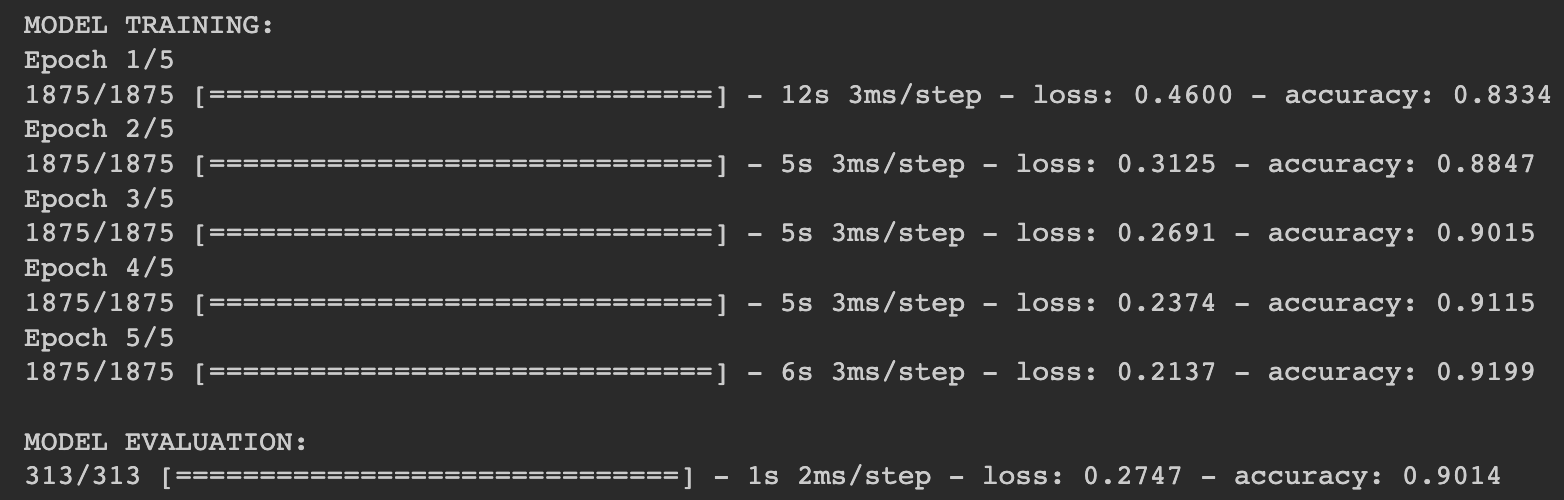
(3) DNN vs CNN
각 Epoch을 확인해 봤을때,
Run Time
DNN: 11s + 4s + 4s+ 4s + 4s = 23s
CNN: 12s + 5s + 5s + 5s + 6s = 34s
Accuracy
DNN: Train은 0.89, Test는 0.87
CNN: Train은 0.91, Test는 0.90
이로써 비록 CNN 이 더 오래걸리더라도 정확성이 더 높은것을 볼 수 있다.
'AI > Deep learning' 카테고리의 다른 글
| M1 mac에서 Tensorflow + PycharmIDE 환경만들기 (0) | 2022.01.22 |
|---|---|
| 2. Computer Vision with Deep Neural Networks (0) | 2022.01.01 |
| 1. The 'Hello World' of Deep Neural Networks (0) | 2022.01.01 |
| 0. 딥러닝 개발 환경설정 (0) | 2022.01.01 |
| 0. 공부 순서 (0) | 2022.01.01 |