머신러닝 프로젝트 라이프 사이클
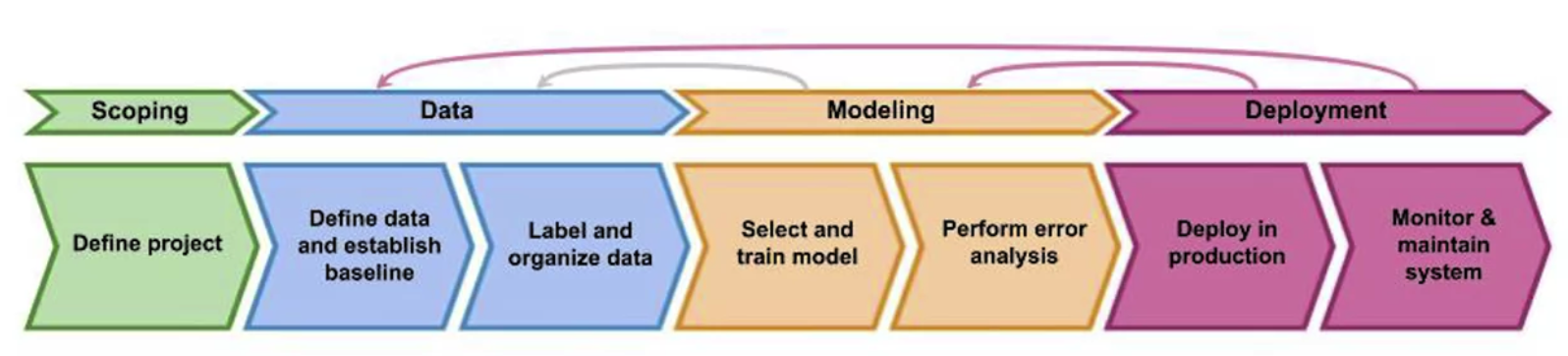
다양한 도메인에서 진행되는 Machine learning 프로젝트에는 공통적인 일련의 과정들이 있다.
기본적으로 데이터 수집부터 시작해서 데이터 사이에서 인사이트를 얻기 위한 EDA, 많은 데이터 중 중요변수만 찾기위한 Feature Engineering, 데이터 결측치 처리 등 데이터의 퀄리티를 높이기 위한 Data Cleansing 등이 있다.
여기서 MLOps는 위에서 말한것들에서 더 나아가 AI 서비스/제품을 배포(Deployment)하기 위한 프로세스까지 커버할 뿐만 아니라 사후관리(Error Analysis)까지 다룬다. 크게 분류하자면 Scoping -> Data -> Modeling -> Deployment로 나눌 수 있다. 이에 대해서 자세히 알아보도록 하자.
1. Scoping
1-1) 프로젝트 정의(문제정의)
가장 먼저 프로젝트를 정의하거나 문제를 정의하여야한다.
간단히 말해서 X -> Y가 되는 X와 Y를 정의해야한다.
- 프로젝트를 정의(문제 정의)한다.
- 현재 보유하고 있는 데이터가 무엇인가?(X 값)
- 프로젝트를 통해 얻고자 하는 결과값은 무엇인가?(Y 값)
- 성과 지표(key metrics)를 설정한다.
예를 들자면 아래와 같은 성과 지표를 의미한다.- Accuracy: 음성 인식 정확도가 어느정도여야 하는지?
- Latency: 음성 인식을 하는데 시간이 얼마나 걸리는지?
- Throughput: 초당 쿼리 처리수은 얼마나 되는지?
- 프로젝트를 수행하는 데 시간이 얼마나 걸리는지?
2. Data
2-1) 데이터 정의
이제 본격적으로 데이터에 대해서 파악해야한다. 아래의 체크리스트를 통해서 스스로 질문해보도록하자.
- 보유하고 있는 데이터 형태가 무엇인가?
- 예측에 필요한 데이터의 양은 충분한가?
- 데이터를 신뢰할 수 있는가?
- 데이터의 레이블이 일정한가?
ex) 음성인식프로젝트에서'음..'을 영어로 어떤사람은 'Um..'이라고 표현하고 어떤사람은 'Umm..'이라고 표현한다.
이를 일관성 있는 레이블로 설정해야한다. - 데이터를 표준화(normalization)한다면 어떻게 할 것인가?
- 라벨링을 한다면, 어떻게 할것인가?
ex) 음성인식프로젝트에서 녹음버튼을 누르고 말하기 전/후에 얼마나 대기시간(silence)을 둘것인가?
머신러닝 분야에서 모델이 잘 동작할거라고 보장하는 데이터의 양에 대한 기준이 엄청 모호하다.
일반적으로 가능한 많이라고 하지만, 링크 게시글의 저자에 따르면, 저자의 프로젝트 경험상 2가지 최소 요건을 파악하여 프로젝트를 진행했다고 한다. 참고하면 좋을것 같다.
- 최소 500개 이상의 데이터
- 데이터 내 variable 수 * 500 이상의 데이터
2-2) 베이스라인 설정
프로젝트를 성공적으로 이끌기 위해서는 명확한 목표가 필요하다.
이 목표를 수립할때는 가장 단순하면서 중요한것이 기존 방식(Traditional Method)은 무엇이고 성능이 어느정도인가? 를 알아야한다.
이는, 머신러닝 프로젝트로 얻은 결과값이 기존보다 얼마나 좋아졌는지 알아 볼 수 있는 지표가 될것이다. 아래 체크리스트를 자문자답해보자.
- 기존방식의 성능은 어떤가?
- 기존보다 대략적으로 얼마나 높일것인가?
2-3) 라벨링(Labeling or Annotation) & 데이터를 정제하는 단계
데이터의 양이 부족하여 추가로 데이터를 수집해야할때 고려해야할 사항이 있다. 우선적으로 어떤 데이터를 수집할것인지? 그 판단의 근거는 무엇인지? 어떤 방식으로 수집할것인지에 관해서 말이다.
- 수많은 데이터 중 중요한 데이터는 무엇인가?
- 데이터 수집 가이드라인을 어떻게 세울것인가?
- 데이터에 라벨링 할 필요가 있다면, 어떻게 할 것인가?
어떤 데이터를 수집할것인지 고려할때 사람이 먼저 예측테스트를 한 결과(HLP(Human-Level Performance)** 를 측정한것과 데이터의 양을 고려하곤한다. 왜냐하면 전반적인 성능을 늘리기 위해서는 단순히 데이터를 무작정 수집하는것이 아니다. 가령 카메라에 찍히는 사람의 인종과 나이를 맞추는 인공지능 모델이 있다고 가정해보자, 평균 성능이 70%라서 추가 데이터를 수집하고 싶다면, 무작정 수집하는것이 아닌, Error Analytics 단계에서 각 라벨의 성능을 확인하여야 하고, 각 라벨의 데이터 갯수를 알아야 한다.대한 판단의 근거로
3. 모델링(Modeling)
3-1) Train할 모델을 선정
다양한 논문이나, 보고서들을 보면 고정된 데이터를 토대로 알고리즘을 개발하여 성능을 향상시킨다.
이처럼, AI 모델학습을 하다보면 느끼게 될것 중 하나가 반복되는 작업이 굉장히 많다는 것이다. 여러 모델을 학습시켜 실험해보고, 하이퍼파라메터를 다양하게 조합하면서 이렇게까지 엄청난 시간이 소요된다.
이 과정을 거치면서 오류분석을 하다보면 최적의 모델 선정할 수 있게된다.
2) 오류 원인 분석(Error Analytics)
오류의 원인으로는 다양한 이유가 있을것이다. 선택한 모델 성능이 떨어지거나, 데이터의 수가 부족하거나 등등이다. 머신러닝 시스템을 배포하기 전의 과정으로써 다음과 같은 질문을 끝으로 최종 검사를 할 수 있을것다.
- 성능이 베이스라인(Baseline) 혹은 목표치(Goal)를 달성할 만큼 우수한가?
- 데이터 수가 충분하여 신뢰할만 한가? (부족하다고 판단될경우 전단계로 돌아간다)
4. 배포(Deployment)
4-1) 제품 배포
이제 AI 제품/서비스를 배포하는 시점이다. 아래 그림처럼 만약 음성인식 시스템이라 가정하면,학습시킨 모델을 클라우드내에 두고 운용할것인지? 아니면 모바일 폰 내에 작은 모델을 둘것인지? 와 같은 아키텍처부분에 대한 고민일 것이다.. 자세한 부분은 추후에 더 살펴보기로 하겠다.
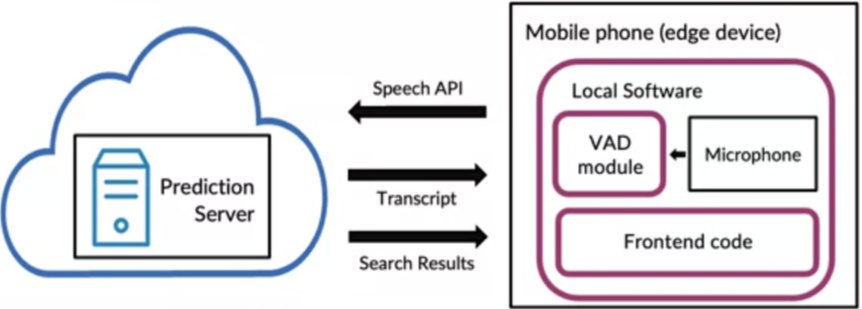
만약, 이 단계에 돌입한 시점이 처음이라면 여기까지가 머신러닝 프로젝트의 고작 50% 밖에 차지하지 않는다.
4-2) 모니터링 & 시스템 유지
Deployment 이후 시스템 유지를 위한 유지보수단계가 나머지 50%을 차지한다고 생각하면 된다.
가장 까다로운 작업 중 하나로 ML 성능을 유지 및 개선하기 위해 모니터링 하는 곳이다. 계속 들어오는 데이터를 추적하고, 시스템을 유지 관리해야 한다.
예를들면 다음과 같은 질문이 있을 수 있다.
- Concept drift와 같이 데이터 분포가 변경되면 모델을 새로 업데이트 시켜야할지?
- Batch 주기를 어느정도로 할지?
위와 같은 고민들 외에 굉장히 많을텐데 위 같은 경우에는 오류 분석하기 위해 Data 단계로 돌아가서 새로운 정의에 따라 데이터를 수집하거나, Model 단계로 돌아서 모델을 재 훈련시켜야한다.
99. 용어정리
(1) POC(Proof Of Concept; 개념 증명)
POC 단계의 요점은 '솔루션' 및 '솔루션의 주요 기능'에 대한 타당성 증명하는 절차를 의미한다.
일반적으로 아래의 질문을 통해서 POC가 이루어진다.
- 이 기술로 요구사항 충족이 가능한가?
- 이 제품은 광고된대로 작동하는가?
- 궁극적인 솔루션이 될 수 있는가?
- 성공 기준 정의
- 제안된 솔루션의 엔지니어링
- 성공 기준에 대한 솔루션 평가
- 향후 진행 여부 결정
즉, POC는 '기존에 없던 솔루션을 프로젝트에 도입하기 앞서 검증을 하는 단계' 라고 표현할 수 있다.
(2) Pilot 단계
Pilot 단계는 배포 규모에 따라 몇 주 ~ 몇 달까지 단계별 접근 방식으로 구현된다. 일반적으로 아래와 같은 사항이 진행되어 성공에 가까워지면 환경을 Production으로 이동합니다.
- 비즈니스 및 기술 요구사항 평가 기반 세부 아키텍처 설계
- 환경 구축 및 구성
- 장애 조치, 높은 가용성 및 확장성 검증을 위한 인프라 테스트
- UX 최적화를 위한 사용자 테스트 및 반복적 피드백
- Pilot 사용자 및 help desk를 위한 문서와 교육
즉, Pilot이란, '소규모로 진행하는 시험 프로젝트 단계' 라고 표현할 수 있다.
(3) Production
Production의 의미는 다양하게 해석될 수 있는데, 여기서의 Production은 환경에서 제공하는 서비스가 핵심 업무 역할을 제공하는 데 사용되도록 모든 사용자에게 배포된다는 개념입니다. 일반적으로 아래와 같은 사항이 진행되어야 한다.
- End User 및 help desk 지원을 위한 공식 교육
- 새로운 시스템으로의 전환을 위한 공식 일정 및 커뮤니케이션
- 공식적인 운영 및 지원 조직 / 프로세스에 환경 배치
- 비즈니스 sign off(승인)
즉, Production이란, 사용에 있어 정상적인 상태(steady state)를 유지하는 단계 라고 할 수 있다.
4) 홀드아웃(Hold-Out)

홀드아웃 교차 검증 방식은 전통적이고 널리 사용되는 머신러닝 모델의 성능 추정 방법이다. 이 방식은 전체 데이터셋을 2가지로 나누는데 훈련 세트(train set)와 테스트 세트(testset)로 나눈다.
여기서 훈련세트는 모델을 훈련할때 사용하고 테스트 세트는 훈련된 모델의 성능을 측정하는데에 사용합니다. 일반적으로 7-80%를 훈련세트, 2-30%를 테스트 세트로 사용한다.
하지만 통용적으로 훈련세트에서 검증세트(Validation set)을 한번 더 나눈다. 그렇게 해서 초기 데이터는 훈련 세트, 검증 세트, 테스트 세트 세 개로 나눠질 수 있다.
여기서 훈련 세트는 위에서 말했듯, 여러 가지 모델을 훈련하는 데 사용하고, 검증 세트는 모델의 하이퍼파라메터를 수정하고 테스트 과정을 거쳐 모델을 최종 선택하는 과정으로 사용하며 마지막으로, 테스트 세트는 배포전 최종 성능 측정을 하는데에 사용합니다.
이것은 훈련세트와 검증세트를 차례로 거쳐 모델을 선정하고 테스트 세트로 데이터를 분리했기 때문에 새로운 데이터에 대해 덜 편향되게 추정할 수 있다는 장점을 가지고 있습니다.
본 포스팅은 Coursera의 MLOps 특화 과정을 학습하며 정리한 정리노트입니다.
추가 참조 출처
https://www.coursera.org/specializations/machine-learning-engineering-for-production-mlops?
https://velog.io/@stu_dy/IT%EC%9A%A9%EC%96%B4POCPilotProduction
'AI > MLOps' 카테고리의 다른 글
| (3) 머신러닝 시스템 배포(Deployment & Monitoring) (0) | 2022.01.16 |
|---|---|
| (1) What is the MLOps? (0) | 2022.01.07 |
| 0. MLOps 공부 자료 (0) | 2022.01.03 |